TURKISH SENTIMENT DATASET
In publications using the datasets, cite as:
Hayran
, A., Sert, M. (2017), "Sentiment Analysis on Microblog Data based on Word Embedding and Fusion Techniques", IEEE 25th Signal Processing and Communications Applications Conference (SIU 2017), Belek, Turkey, pp. xx-yy.BIBTEX:
BIBTEX:
@INPROCEEDINGS{hayran_sert_2017,
author={A. Hayran and M. Sert},
booktitle={2017 25th Signal Processing and Communication Application Conference (SIU)},
title={Analysis on Microblog Data based on Word Embedding and Fusion Techniques},
year={2017},
pages={tbd},
doi={tbd},
month={May}
}
author={A. Hayran and M. Sert},
booktitle={2017 25th Signal Processing and Communication Application Conference (SIU)},
title={Analysis on Microblog Data based on Word Embedding and Fusion Techniques},
year={2017},
pages={tbd},
doi={tbd},
month={May}
}
 ABSTRACT
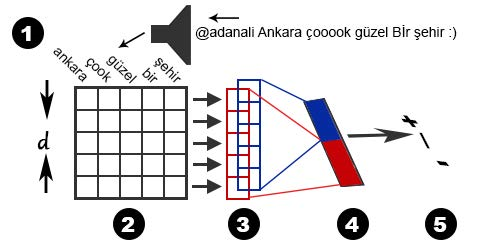
ABSTRACT People often use social platforms to state their views and desires. Twitter is one of the most popular microblog service used for this purpose. In this study, we propose a new approach for automatically classifying the sentiment of microblog messages. The proposed approach is based on utilizing robust feature representation and fusion. We make use of word embedding technique as the feature representation and the Support Vector Machine as the classifier. In our approach, we first calculate statistical measures from word embedding representations and fuse them using different combinations. Learning is performed using these fused features and tested on the Turkish tweet dataset. Results show that the proposed approach significantly reduces the dimension of tweet representation and enhances sentiment classification accuracy. Best performance is attained by the proposed Dvot fusion technique with an accuracy of %80.05.
DATA:
To obtain the Turkish Sentiment Dataset, please send an email to here with subject line containing "Sentiment Dataset Request". The data is available for free for academics and therefore the email must come from an academic institutional email address.