Hello! Right ~ we meet again! It feels like a short time that you have
passed through this far. I'm sure you've finally made it. You're pretty
smart! The last lesson wouldn't be a hindrance
to you. Now, I'm going to discuss multiple dimensional linked list. I think
this has quite a broad use, so I included it here. If you think this chapter
boring, you can skip it. :-)
Yeah! We're going to learn multiple dimensional linked list, MDL for short. What the heck is that? That's like chaining list in multiple direction. In queue or stack, we link each node in one direction. In double linked list, we link each node in two direction. In tree, we link each node to several direction: to the parent, to the brothers, and to the first child. Now, in MDL, we just be able to link each node to other arbitrary nodes. Which nodes? Random, it's all depend on the conditions. Just like in a map. One city is linked to other cities with highways or may be roads. Suppose that city has three ways to go to another city. Another city is not always have three ways to go outside that city, it may have just 2, or 4, or may be 9. That's the analogy of MDL.
Actually, this chapter is a part of graph or digraph in the third lesson. If I don't separate it here, the graph or digraph part will be incredibly long. :-) There so many things to discuss. Mostly, this study is directed into Artificial Intelligence (AI) things. Well, I like AI so much. It's the computer's future. I'm not going to discuss the AI stuff here, but I'm just explaining the basics. May be I will put the AI things in the advanced material.
The common use of this part is to seek the shortest path from a city
to another city. Other use is to implement a knowledge base. That is commonly
used for linking pieces of knowledge. We are know that knowledge is hyperlinked.
Yeah, MDL is a suitable structure for this. This is an exampple why the
knowledge is hyperlinked. Say like oxygene. Oxygene is a gas. Its chemical
structure is O2. While gas is not just oxygene, it may be linked
to nitrogene, carbon dioxide, and many others. While carbon dioxide is
needed by green plants to breathe. And so on. I'm sure that you're too
smart to get the idea. :-)
Sure, we always discuss the beginning first. :-) At the beginning, we
just talk about how to implement the MDL into programming language structure,
such as record. Yep, this is not hard though:
pMDL = ^tMDL; pLinks = ^tLinks;tMDL = record { Node data definition } num : byte; { Any data can be put here } tag : byte; { This is a tag, needed for searching } firstlink: pLinks; end; tLinks = record { Link-node data definition } distance : byte; where : pMDL; { Points to a node } otherlink: pLinks; { Points to another link } end;
Seemed that it goes further than a tree, right? Two record definitions is needed. One for the node, and the other for the link. Node definition contains the real data. Because we don't know how many links the node will be linked, we just store the first link. Just like general tree, we need only store the link to the first son.
The link now is not simply a pointer, it's a data definition, called link-node. It contains which node it points to and it also store the link to other link-node. Usually, the link-node brotherhood is queue. However, you can make it into double linked list as well. You can add the distance in link-node here. It is fully optional. You can add it as you want to. This variable (distance) has a clear use, for weighted calculations. For example, the city A and B is connected by a road with a distance of 6 miles. Then, we put 6 in distance.
OK, I suppose all the terms are clear now. Let's get into it. First,
adding part. Adding part is not trivial. You can modify the general tree's
add function to this. However, we must take care of the real condition.
Suppose you want to build a map, then you must see the real map drawing.
If the map says city A and B are connected, then you must do so. It is
either adding A from B or B from A.
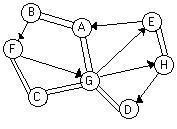
Still murky, eh? Now look at this picture:
Suppose above is a map. There are cities denoted by A, B, C, D, through H. If between city is connected by two lines, it means that we can go freely back and forth. Look at city A and B. It is connected by two lines. It means we can go either direction, from A to B or from B to A. But if the cities is connected by only one line, like F and G. The direction shows where we could go. So, we can go from F to G, but we can't go from G to F.
Suppose we add A first into MDL, then B, C, D, ... H. Then do this:
The conclusion is that we need add and connect routines. Adding nodes mean that after we create that node, we connect it with the parent. Connecting nodes mean that we just create the link-node, then we link it. Easy right?
Now, the tag field in the link structure. It is for searching. Suppose we need to search the shortest path, say from H to C. We do techniques called Dijkstra's technique. It's all because he invented it. The technique will be discussed later, not in this lesson. It is pretty complicated.
We need not build the display part. We just draw a map and put it on the screen. If we build knowledge base, we need not even draw it on the screen. Everything is done abstractly. That's why many programmers often fall even in a simple trap. How about deletion and insertion? We don't need them either. It is not practical, except when we build knowledge base. If we build knowledge base and the knowledge in our database is obsolete, we need to delete it. However, obsolete knowledge is usually not thrown away. It was marked as 'obsolete' instead.
Insertion (in knowledge base) occurs when new knowledge is invented or inputted by user. It is usually the knowledge that abridges two or more existing knowledge. However, it is also rarely done. Suppose we have knowledge A and B connected each other. Then, later we have knowledge C that actually placed between A and B. We don't need to do so. We let knowledge A and B intact, then we connect knowledge A with C, then knowledge B with C.
Destroying? Upon exiting? Yes! We need to destroy the MDL in the memory.
It is done recursively. However, we must pay attention to how we destroy
MDL. It is not simply a recursive matter. It is complicated! Fortunately
Pascal has a special function called mark and release.
We need a marker pointer to get around with this. Declare an untyped pointer
p as follows:
var p : pointer;
Then, before any adding activity happens, put mark(p); in any line, once. The variable p will act as a marker. Upon destroying, you just put release(p); to make things easy. Voila! The destroying is done! Easy, right?
Before we end this lesson, I want to talk about controlling memory. Remember {$I-} to keep the I/O part calm in the first lesson? Now, I'll add the {$M} to control memory usage. $M takes parameters which varies in DOS real mode programming, protected mode programming, or Windows programming. This time, I'd like to discuss the real programming only.
The syntax is:
{$M stacksize, heapmin, heapmax }
Stacksize is 16384 in default. Heapmin and heapmax default value are respectively 0 and 655360. All parameters are in integer. Consult your Pascal's help file about the maximum or minimum value. Usually stacksize ranges from 1024 and 65536, and the value should be 2n (i.e. 2, 4, 8, 16, 32, ...). Heapmin and heapmax range from 0 to 655360, any number you like. However, heapmin must be less or equal than heapmax.
You need to enlarge the stacksize only if you have a procedure or a functions that takes a lot of parameters. Stack here is not the stack I have taught. Although the main principle is the same (LIFO), but stack in here is not a single linked list. This kind of stack is usually used by CPU and we may use it intensely in low-level programming, which I'll explain in later chapters. But now, as the rule of thumb, just accept the above fact.
Heapmin here is used for specifying how-many-bytes-of-memory-in-minimum should Pascal reserve for you to use in linked list. And heapmax, to specify the maximum value.
That's all folks! Not quite long, right? Shall we go to the quiz or the next lesson?
Back to main page
Back to Pascal Tutorial Lesson 2 contents
To the quiz
To Chapter 6 about BGI Graphics part 1
My page of programming link
Contact me here
By: Roby Johanes, © 1997, 2000